

UFC Fight Predictor
Summary
For this project I engineered an algorithm that perdicts the outcomes of UFC fights. To accomplish this, I trained a model to predict the outcomes of fights using pre fight data. In this paper I go into the specifics of how everything was designed and implemented.
Inspiration
This project started during my last semester at college; Feb 2020. I had a lot of free time on my hands and couldn't find a Kaggle Competition that interested me. I decided to challenge myself and see if I could predict the outcomes of UFC fights using pre fight data.
Data Collection
In order to start this project, I needed to find historic UFC data. Upon forum scraping, I found an old UFC fight stats web scrapper. I quickly implemented this into my pipeline and updated it to scrape all UFC data up until the current date. This now allowed me to build a system in which I would always have the most up to date fighter statistics.
Preprocessing
The format in which the scrapper returned the data was in the form of end of fight data. Essentially, a row of data contained that fights statistics (i.e. total punches thrown or total takedown attemps). This is fine for playing with the data to see interesting stats, but isn't correct format for predicting. In order to predict I would need the rows to look like both fighters pre fight stats, with the last element in the row being the actual result. One stat that stuck out the most was that the higher ranked fighter wins ~63% of the time and this even goes up to ~81% for title fights. To the data scientist this might makes sense, of course the higher ranked fighter wins more... they are higher ranked. However, I am not just a data scientist, I am also a UFC fanatic. So, to me, this stuck out as interesting. When you are watching the fights it almost feels random, this stat alone breaks that illusion. This was proof to me that this would be possible, so I then got the data in the correct format, and started the feature engineering.
Feature Engineering
After "getting to know" the dataset, it was time to feature engineer. Now obvioulsy this step isn't necessarily only done before the model training and testing. In fact, I iteratively would feature engineer then train and test the models, and repeat. For the sake of flow, I will explain this before the model creation explanation. I used the knowledge I learned from observing the data set and intuition to create multiple new potential super features. A super feature is essentially anything we add to the data that boosts the accuracy a meaningful amount. Explaining everything I did would take a lot of time, so I will explain the coolest feature created. I created an algorithm that went through all of the data and gave each fighter a score before each fight. This score was based on the culmination of their last fights. The score is calculated by seeing who they beat/lost to recently, and how much better/worse their opponent was at the time. Below is my internal visualization of Khabib Nurmagommedov's career. This data is not the data used for prediction. This is created in order to calculate resume scores. "opp" stands for opponent, and the row is some information about the opponent before the fight, with some stats about Khabib (represented by "my_...") before the fight as well. These are the stats that help figure out how much better/worse the opponent was before the fight, which helps increment/decrement the score depending on the result (Win, Loss or Draw). A title fight is a fight for the championship belt; the belt represents the person who is the best at their weight class.
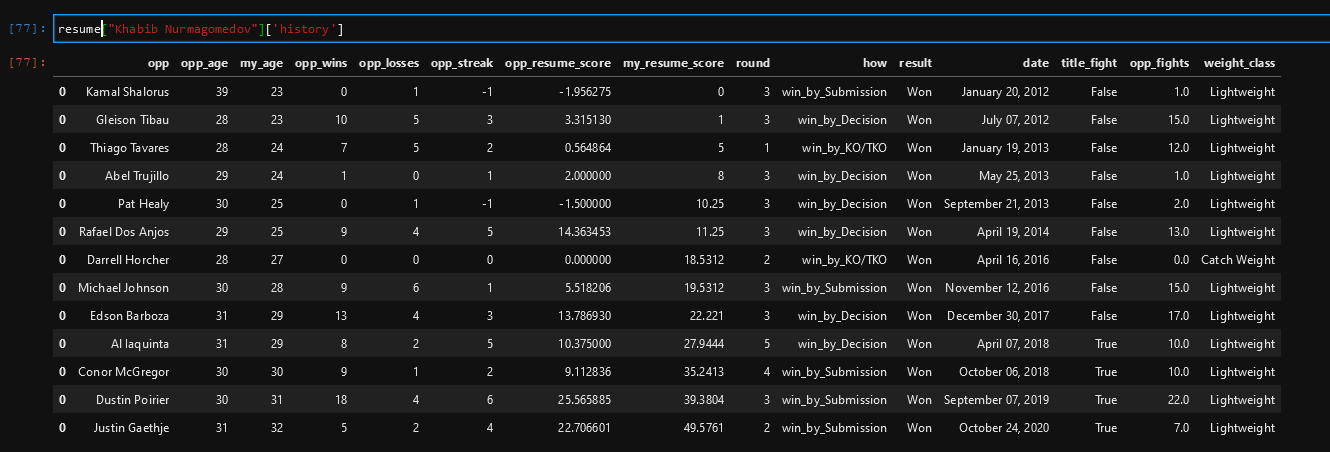
Resume Visualization
Using the internal resume score I created, and the resume object which holds every fighters career, I was also actually able to create a list of the best fighters of all, time according to the algorithm. This doesn't help predict anything, I just thought this was really cool. My algorithms top 6 actually matches most analysts (give or take).
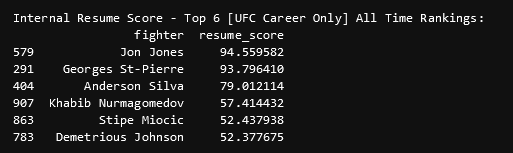
The Algorithm's Top 6 UFC Fighters of All Time
Once again, the feature engineering and the model training and testing are done iteratively. Meaning a lot of the features I ended up with were created on the 6th iteration and so on. Just want that to be clear so it doesn't look like I had just one shotted all of these features and then trained. That would be missrepresenting the tedious amount of back and forth this lovely project had :) .
Model Training & Testing
This part is honestly the easiest part of the whole process. Once the data is formatted in the correct way, it is really just matching the model architecture to the problem space. My dataset is only 8k rows so most the model types are fine to use, it will just depend on what parameters are used.
Model Performance Vs Size
I ended up going with an XGBoost model. This stands for extreme gradient boosted trees; these essentially balance complexity and loss very well. They are great at lowering loss without hyperfitting to the data; as long as I dont set some large depth size manually. After running the initial training, I used the validation set for hyperparameter tuning using GridSearchCV. Finally I tested the model and got the results below.
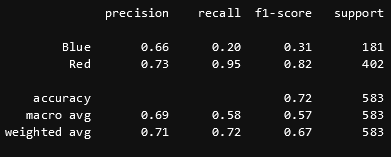
Confusion Matrix
The results for red corner predictions are great, whereas the blue corner predictions are pretty poor. This is due to the unbalanced nature of the data. I cannot balance it because the posterior probabilities represented by the unbalanced is true to the sport. To fix this I am working on a scaling feature to null out red and blue corners, and therefore allow me to balance the data and get a more balanced result. All that aside, this f1 score is pretty good, and is better than any verified UFC model that I have read about. I am working on this everyday to make it better.
Predicting Real Events
I have built a full pipeline that allows me to have up to date statistics on all fighters, which allows me to run predictions on any upcoming fight I want. In fact, I have predicted every card the UFC has had since last May, without missing one! Below is an example for how the output looks.
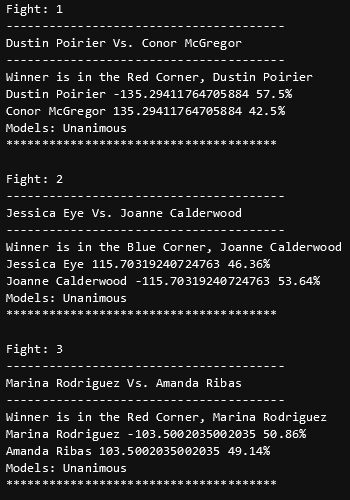
Example Output for UFC 257
These predictions all came out to be correct, which is always fun to see. I predict all fights on the UFC card in which both fighters have at least 1 fight in the UFC. The above picture is 3 of the 10 fights predicted for UFC 257's card. All predictions made are saved to a MongoDB instance (No-SQL Database), as part of my pipeline. To see how these predicitons are used, go back to my homepage and view my "Algorithmic Sports Betting" project.
View the Code
I have this repository private, as I do not want anyone to steal this code. There are things I do that I can potentially sell so I cannot have this repo public. However, if you want a runthrough of this code, contact me here.